2023年数据分析师还有前途吗?
15年,你会用个Excel,透视表玩的6,再会用SQL查询数据,就能找到很好的工作。
17年,你还得会用各种BI可视化工具,用Tableau做一些漂亮的图表,才能找到很好的工作。
20年,你还得会python,写一些自动化的脚本来解决日常重复的工作,才能找到很好的工作。
23年,你除了要会上述提到的技能,还要懂爬虫,还要懂算法,还要懂..........;才能站稳数据分析师的岗位。
接下来我们就用实战走一遍上述技能的全栈流程(文章中提到的数据不商用,不对外售卖,仅个人使用,望理解!)。
全栈路线: 数据采集——>数据清洗——>入库——>统计分析——>挖掘——>可视化;
一、数据采集
博主本人是从事汽车行业的分析师,所以会拿汽车行业的相关数据举例;
我们现在手里没有数据,怎么办?一个字——【爬】,我本次的案例是爬取某网站开源的数据,并且没有对该网站做任何的破坏、攻击等不利行为,下述文章中隐藏该网站url,如读者想深度讨论,可与我私聊;
import requests
import pandas as pd
import random
import time
from datetime import datetime
from lxml import etree
# 参数区,每次需要更改时间和页面数量
date = '2022-01'
page = 666
headers = {
'user-agent':'在开发者工具中寻找自己的agent',
'Cookie':'在开发者工具中寻找自己的cookie'
}
# 创建一个空的DataFrame
data = pd.DataFrame(columns=['排名', '车型', '城市', '上牌量', '级别', '指导价(万元)'])
time_start = datetime.now()
for i in range(1,page+1,1):
print(f"开始爬取第{i}页")
#地址
url = f'https://url{date}url{i}.html'
#请求地址
resp = requests.get(url,headers = headers)
resp.close()
# 解析HTML
tree = etree.HTML(resp.text)
# 使用XPath提取数据
rows = tree.xpath('//html/body/div[5]/div[3]/div[2]/div[2]/table/tbody/tr')
# 遍历每一行数据并添加到DataFrame中
for row in rows:
rank = row.xpath('./td[1]/strong/text()')[0]
model = row.xpath('./td[2]/a/text()')[0]
city = row.xpath('./td[3]/a/text()')[0]
sales = row.xpath('./td[4]/a/em/text()')[0]
category = row.xpath('./td[5]/a/text()')[0]
price = row.xpath('./td[6]/a/span/text()')[0]
#依次注入最新数据
data = pd.concat([data, pd.DataFrame({'排名': [rank], '车型': [model], '城市': [city], '上牌量': [sales], '级别': [category], '指导价(万元)': [price]})], ignore_index=True)
# 为避免反扒 和 保护该网站 ,将每次的爬取时间设置的长一点,在6-11秒随机停顿一会
time.sleep(random.randint(6, 11))
print(f"第{i}页怕取完成")
# 查看爬取进度
time_end = datetime.now()
print("已耗时" + str(time_end - time_start))
print(f"还剩下{page - i}页,预计花费{round(((page-i)*8.5/60),2)}min")
if(i%50 == 0):
data.to_excel(f"{date}全国车型上险数据.xlsx")
print("爬取完成")
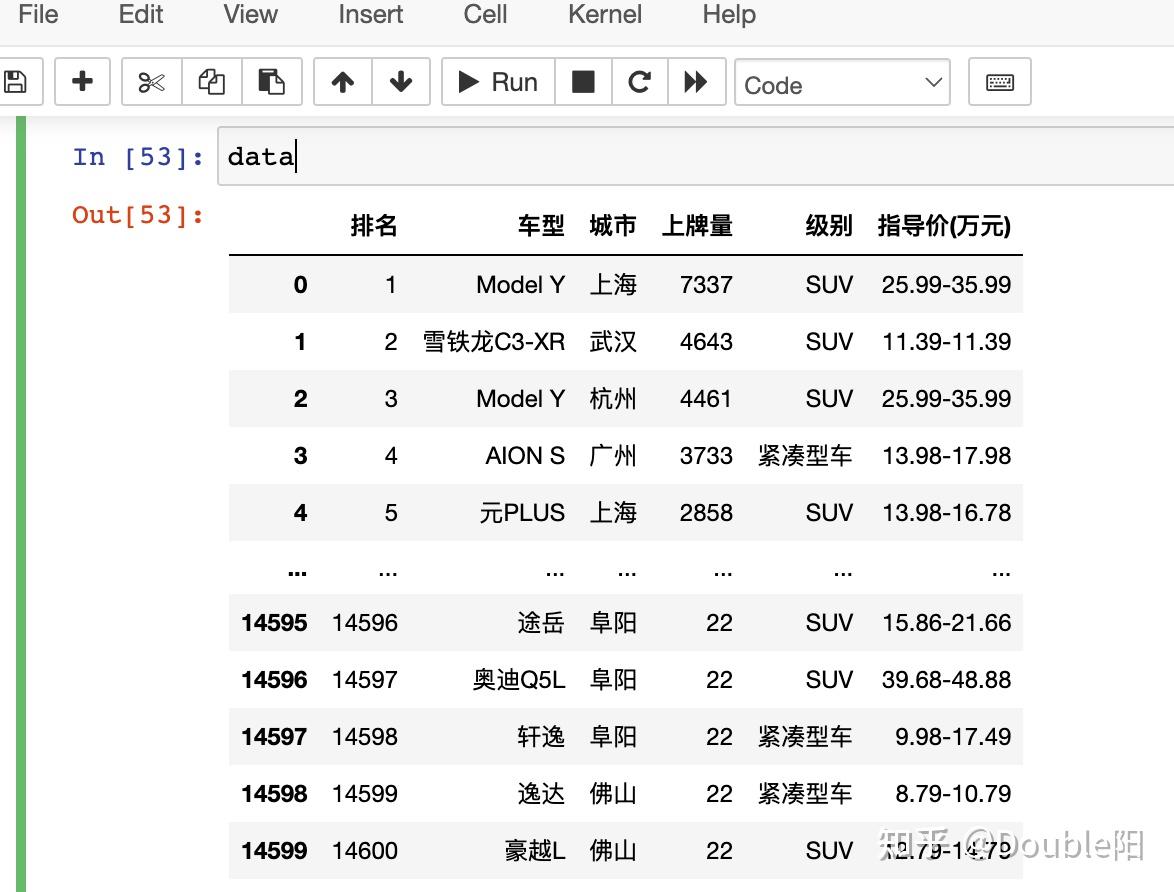
以上代码运行完毕,会得到一份如下图所示的数据(图1-1),该数据包含了,2022年全年——2023年截止至今的车型by城市的销量数据。
二、清洗
清洗是数据工作中很头疼的内容,
它不仅考验你的技术功底(用各种千奇百怪、五花八门的技巧来解决数据问题)
还考验你对业务的理解程度(要找到车型品牌的映射关系表,也就是还需要再爬取一遍其他网站的数据,你最终要校验清洗结果是否准确,所以你脑子里要了解每款车型对应的品牌是什么,这就需要沉淀了)
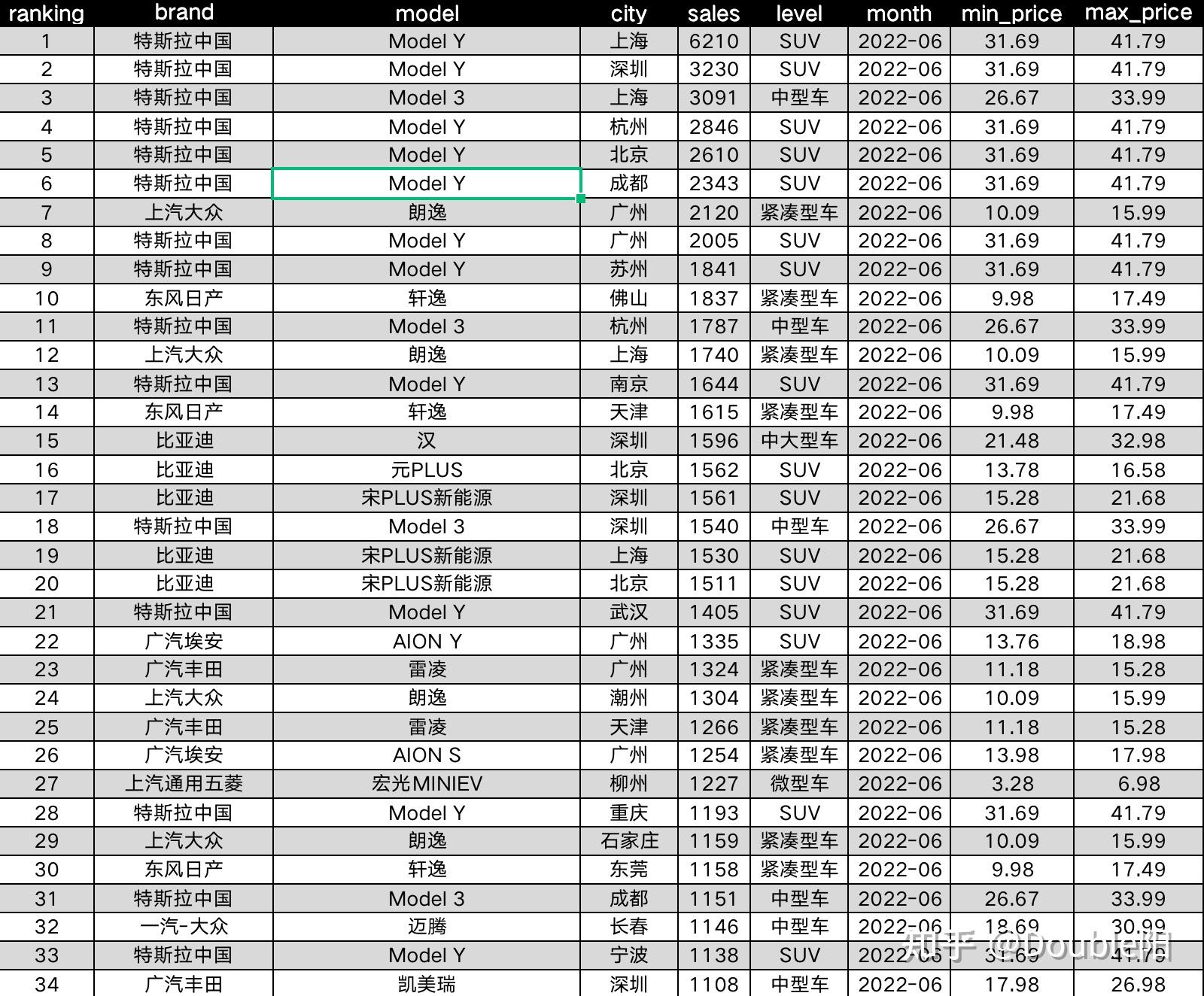
以上过程较为复杂,且方向很定制化,该过程不做描述,直接展示清洗后的结果,如下图1-2。
三、入库
我这里使用的是mysql数据库,具体的安装流程见如下链接:
mac装mysql?接下来我们用python连接mysql服务器,将数据库存入mysql
import pandas as pd
import mysql.connector
# 建立数据库连接
conn = mysql.connector.connect(
host='localhost',
user='root',
password='password',
database='car_data'
)
cursor = conn.cursor()
# 读取Excel文件
excel_data = pd.read_excel(f'data_source.xlsx')
# 循环遍历Excel数据,并插入数据库
for index, row in excel_data.iterrows():
# 替换为Excel中相应字段的名称
ranking = row['ranking']
brand = row['brand']
model = row['model']
city = row['city']
sales = row['sales']
level = row['level']
month = row['month']
min_price = row['min_price']
max_price = row['max_price']
# 构建插入语句
sql = "INSERT INTO cars_insurance_sales (ranking, brand, model, city, sales, level, month, min_price, max_price) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)"
# 执行插入语句
values = (ranking, brand, model, city, sales, level, month, min_price, max_price)
cursor.execute(sql, values)
# 提交更改并关闭连接
conn.commit()
cursor.close()
conn.close()
print("数据全部插入完成")
四、统计分析
数据已经准备好了,接下来我们做点好玩的事情
我们先来看一下北京哪些品牌卖的好,如果直观的把每个品牌做销量降序没有意思,我们引入一个观点,把品牌定级,占据北京前30%销量的品牌列为头部品牌,中间40%销量的品牌列为腰部品牌,最后30%销量的品牌列为尾部品牌,此处需要用到mysql的窗口函数sum() over(partition by [] order by []),具体方案如下:
import pandas as pd
import mysql.connector
import matplotlib.pyplot as plt
# 建立数据库连接
conn = mysql.connector.connect(
host='localhost',
user='root',
password='password',
database='car_data'
)
# 创建游标对象
cursor = conn.cursor()
# 执行SQL查询
query = """
SELECT
*,
CASE
WHEN accumulate_rate <= 0.3 THEN
'high'
WHEN accumulate_rate <= 0.7 THEN
'mid' ELSE 'low'
END car_in_city_level
FROM
(
SELECT
*,
LEAD( accumulate_rate, 1 ) over () lead_accumulate_rate
FROM
(
SELECT MONTH
,
brand,
city,
sales,
sum( sales ) over ( PARTITION BY MONTH, city ORDER BY sales DESC ) accumulate,
sum( sales ) over ( PARTITION BY MONTH, city ) total,
sales / sum( sales ) over ( PARTITION BY MONTH, city ) rate,
sum( sales ) over ( PARTITION BY MONTH, city ORDER BY sales DESC ) / sum( sales ) over ( PARTITION BY MONTH, city ) accumulate_rate
FROM
( SELECT MONTH, brand, city, sum( Sales ) sales FROM cars_insurance_sales GROUP BY MONTH, brand, city ) inner_table
) inner_table
) assist_table
"""
cursor.execute(query)
# 获取查询结果
sql_result = pd.DataFrame(cursor.fetchall())
# 设置字体为 Arial Unicode MS
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
# 筛选北京22年6月的数据
data = sql_result[sql_result["city"].str.contains("北京")&sql_result["month"].str.contains("2022-06")]
# 分别筛选头部、腰部和尾部品牌的数据
top_brands = data[data['cumulative_sales_percentage'] <= 0.3].reset_index(drop=True)
middle_brands = data[(data['cumulative_sales_percentage'] > 0.3) & (data['cumulative_sales_percentage'] <= 0.7)].reset_index(drop=True)
bottom_brands = data[data['cumulative_sales_percentage'] > 0.7].reset_index(drop=True)
# 创建图表
fig, ax = plt.subplots(figsize=(25, 12))
# 绘制条形图
top_bars = ax.bar(top_brands['brand'], top_brands['sales'], color='green', label='Top Brands')
middle_bars = ax.bar(middle_brands['brand'], middle_brands['sales'], color='orange', label='Middle Brands')
bottom_bars = ax.bar(bottom_brands['brand'], bottom_brands['sales'], color='red', label='Bottom Brands')
# 添加数据标签
def add_labels(bars, data_column):
for i, bar in enumerate(bars):
height = bar.get_height()
percentage = data_column[i]
ax.text(bar.get_x() + bar.get_width() / 2, height, f'{height} ({percentage*100:.1f}%)', ha='center', va='bottom', rotation='vertical')
add_labels(top_bars, top_brands['cumulative_sales_percentage'])
add_labels(middle_bars, middlbrands['cumulative_sales_percentage'])
add_labels(bottom_bars, bottom_brands['cumulative_sales_percentage'])
# 设置图表标题和轴标签
ax.set_title('Top, Middle, and Bottom Brands in beijing')
ax.set_xlabel('Brand')
ax.set_ylabel('Sales')
# 添加图例
ax.legend()
# 调整x轴标签的旋转角度和间距
ax.set_xticks(range(len(data['brand'])))
ax.set_xticklabels(data['brand'], rotation='vertical', ha='center')
# 调整图表布局
plt.tight_layout()
# 保存图表
plt.savefig('sales_chart.png', dpi=300)
# 显示图表
plt.show()
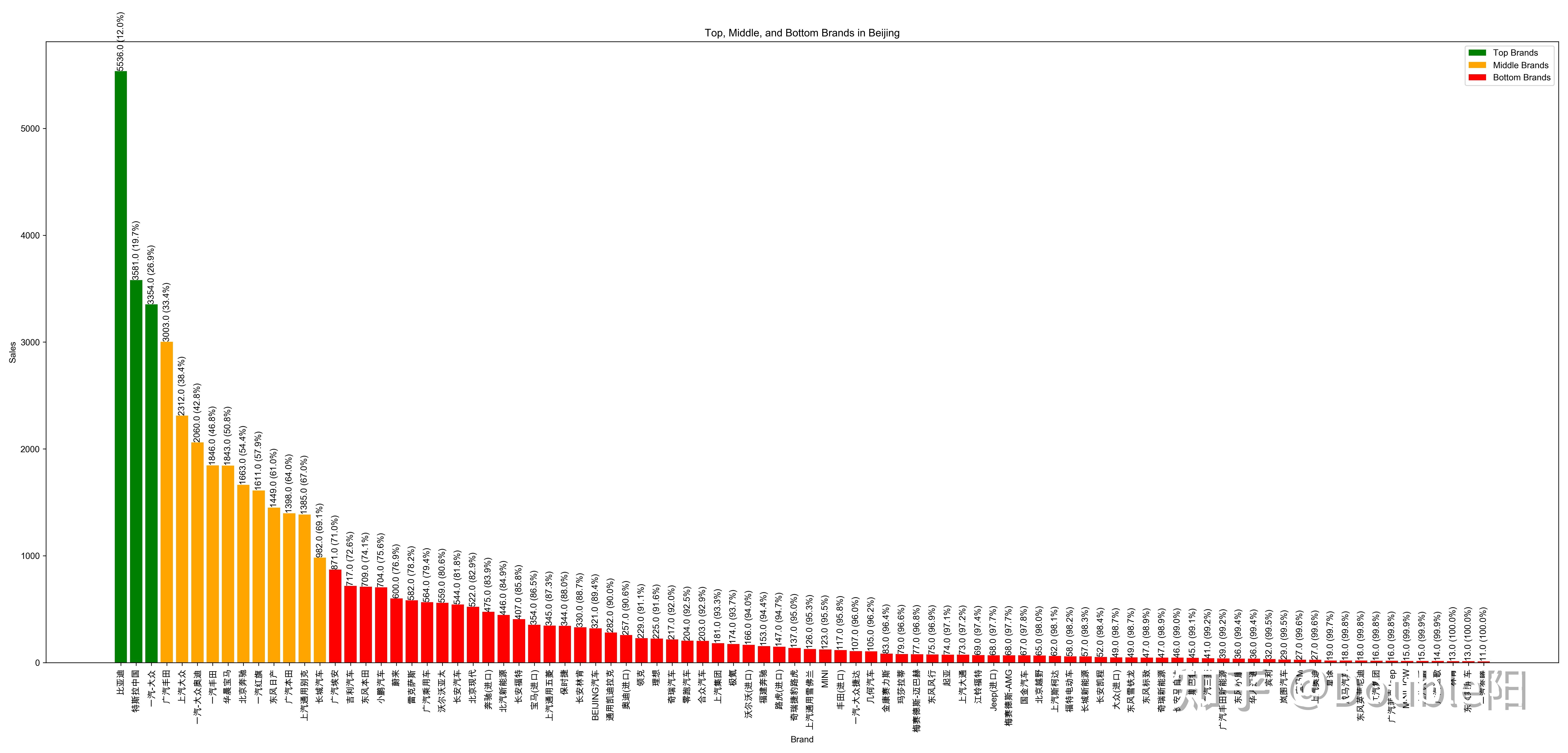
最终运行结果如下图1-3,可以得到的结论如下
- 可以直观的看到北京的头部品牌为比亚迪、特斯拉、一汽大众,腰部品牌为广汽丰田、上汽大众、奥迪、宝马等,尾部品牌广汽埃安、吉利汽车、小鹏、尉来等。以及每个品牌的对应的销量。
- 当某个行业发展到一定规模,一定会趋近二八定律(80%的市场份额掌握在20%的玩家手中),汽车市场也是如此,如下图所示总计90个品牌,前20个品牌几乎占据了全北京80%的销量!!!
五、数据挖掘
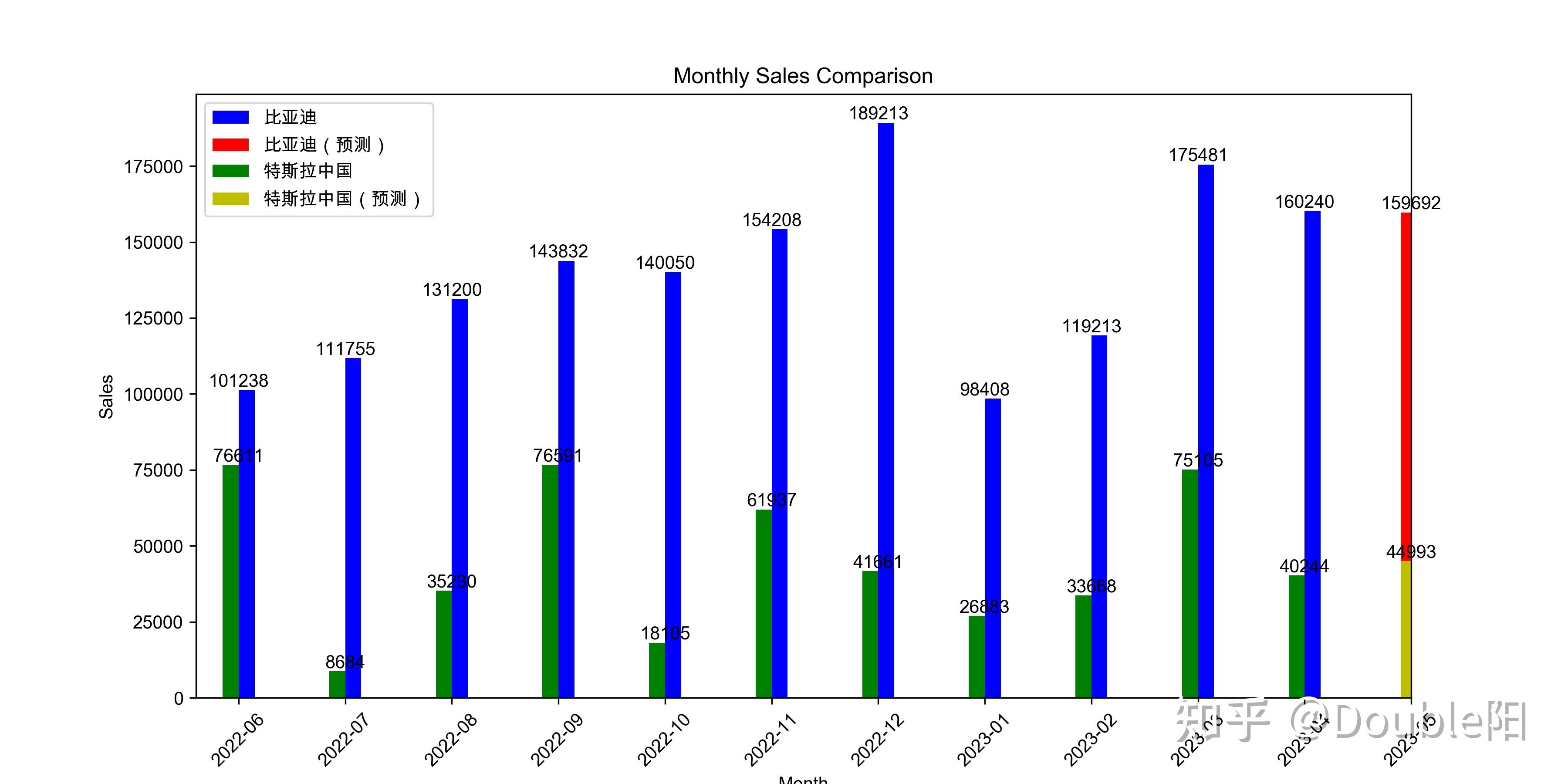
我这里用到的数据挖掘模型是ARIMA模型(差分自回归移动平均模型),是做预测用的,我想看一下目前中国市场上的两个新能源龙头老大(比亚迪和特斯拉)的销量分布是怎样的,并且预测两个品牌下一个月(2023-05)的销量。
import pandas as pd
import numpy as np
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
sql_result['month'] = pd.to_datetime(sql_result['month'])
selected_data = sql_result[(sql_result['month'] >= '2022-06') & (sql_result['month'] <= '2023-05')]
# 按品牌过滤数据
byd_data = selected_data[selected_data['brand'] == '比亚迪']
tesla_data = selected_data[selected_data['brand'] == '特斯拉中国']
# 计算比亚迪和特斯拉的月度销量
byd_sales = byd_data.groupby(byd_data['month'].dt.to_period('M'))['sales'].sum().astype(int)
tesla_sales = tesla_data.groupby(tesla_data['month'].dt.to_period('M'))['sales'].sum().astype(int)
# 创建ARIMA模型对象
model_byd = ARIMA(byd_sales, order=(1, 1, 1))
model_tesla = ARIMA(tesla_sales, order=(1, 1, 1))
# 拟合ARIMA模型
model_byd_fit = model_byd.fit()
model_tesla_fit = model_tesla.fit()
# 进行未来一个月的销量预测
future_month = pd.to_datetime('2023-05')
byd_prediction = model_byd_fit.forecast(steps=1)[0]
tesla_prediction = model_tesla_fit.forecast(steps=1)[0]
# 可视化图形
fig, ax = plt.subplots(figsize=(12, 6))
# 绘制比亚迪销量
byd_sales.plot(kind='bar', ax=ax, width=0.15, position=0, color='b', label='比亚迪')
ax.bar(len(byd_sales), byd_prediction, width=0.2, color='r', label='比亚迪(预测)')
# 绘制特斯拉销量
tesla_sales.plot(kind='bar', ax=ax, width=0.15, position=1, color='g', label='特斯拉中国')
ax.bar(len(tesla_sales), tesla_prediction, width=0.2, color='y', label='特斯拉中国(预测)')
# 添加数据标签
for i, v in enumerate(byd_sales):
ax.text(i, v, str(v), ha='center', va='bottom')
ax.text(len(byd_sales), byd_prediction, str(int(byd_prediction)), ha='center', va='bottom')
for i, v in enumerate(tesla_sales):
ax.text(i, v, str(v), ha='center', va='bottom')
ax.text(len(tesla_sales), tesla_prediction, str(int(tesla_prediction)), ha='center', va='bottom')
# 设置图形属性
plt.xlabel('Month')
plt.ylabel('Sales')
plt.title('Monthly Sales Comparison')
plt.xticks(range(len(byd_sales.index) + 1), [d.strftime('%Y-%m') for d in byd_sales.index] + [future_month.strftime('%Y-%m')], rotation=45)
plt.legend()
# 保存图表为图片文件
plt.savefig('Monthly_sales_comparison.png', dpi=300)
# 显示图形
plt.show()
运行结果如下图1-4:历史每个月份比亚迪销量都比特斯拉销量高,且差距越来越大,模型预测最新5月的销量同样也是远远领先于特斯拉,比亚迪 国民的骄傲~
另附上我的个人观点:我承认马斯克的特斯拉很酷,但是在中国的市场,不是人人都是特斯拉的受众, 就算频繁的降价但对于大多数中国家庭来说价格还是很高,汽车本就是一款低频重决策的大件产品,如果受众用户不是全部群体会很难再铺开市场,小道消息称特斯拉今年会上市一款平民版本,售价在10W以内,若真的上市,那市场份额就很难预估了,没准还会短暂的打破二八定律也说不准 !!!